“If you want to teach people a new way of thinking, don’t bother trying to teach them. Instead, give them a tool, the use of which will lead to new ways of thinking.”
― Richard Buckminster Fuller
Some of my most eye-opening experiences as an educator came from the years where I trained a student teacher for a semester. As they began their stint by observing my lessons and preparations in their first few days, I inevitably became overwhelmed at the sheer volume – not to mention complexity and nuance – of skills they would need to master over the next several weeks. Skills that become so ingrained in an experienced teacher that they go unnoticed and unappreciated.
And with very few exceptions (like knowing how to quickly silence a group of 35 teenagers with merely a look), those skills transfer to the world outside of the classroom.
-1-
Teachers understand and embrace the learning process.
Technology is always evolving and requires its participants to be lifelong learners.
The technology that we have today will be obsolete tomorrow. As a result, tech not only needs people that have mastered a certain tool or process, but needs people that can be continuously learning and growing. Teachers have a leg up in this arena, since they are so skilled at recognizing – and navigating – the inherent struggles that arise when learning something new. Additionally, teachers operate with a growth mindset perspective, believing that effort and practice can lead to new skills.
-2-
Teachers are experts and sequencing and chunking complex topics in order to make them more understandable.
In technology, problems are solved by breaking them down into smaller problems and tackling them in a logical order.
As a teacher, I was tasked with taking a group of students from an elementary understanding of math to a mastery of algebra within a three-year period. I was successful because I knew how to group, organize and break up concepts so that they could be understood. Those same skills are used in tech, where small chunks of code can be assembled into a larger block or in presenting technological information to a non-tech audience, where you have to be deliberate in your approach.
-3-
Teachers are adept at all forms of communication.
In technology, you have to first listen to understand the problem and then be able to effectively communication the solution.
No field thrives without quality communication both within the business and with stakeholders and/or customers outside the industry. Teachers know how to communicate. Teachers are expert listeners because before you can teach a student, who have to first understand what they know and how they think. Teachers are often effective writers, as they craft everything from directions on a lab to an article for the school website. And of course, teachers excel at presentation since they prepare and deliver these multiple times a day.
-4-
Teachers are expert storytellers, using narrative and visuals to make their content come alive.
Technology often needs people that can synthesize multiple ideas and weave them into a cohesive presentation.
Information is useless if people can’t assimilate it. Whether because of a lack of background knowledge, misconceptions or cognitive biases, it is often a challenge to get people to understand difficult or technical concepts. Teachers know how to build from prior knowledge and use storytelling to uncover and address any previously help beliefs.
-5-
Teachers are nimble in their approach, flexibly trying different solutions until they find the one that works.
Within the tech world, it is also important not to become too wedded to one methodology; a problem-solving mindset is required.
Even though there are certain concepts that I taught every year for my entire career, I never taught them in the same way because the students were not the same. Every day in the classroom provides myriad opportunities for problem-solving and resourcefulness as you have to figure out a way to make it work. Tech is no different. Even if one language or tool is your favorite, it doesn’t mean that it’s the right one for this particular job.
-6-
Teachers are skilled at starting with a longterm goal and then planning backwards what steps are needed to reach that endpoint.
Technology is often trying to solve big problems and it needs people that can strategize how to incrementally reach that solution.
Tech rarely grows in leaps and bounds, rather it uses incremental improvement to increase efficiency or usefulness over time. Teachers are used to this methodology, using repeated observations and assessments to measure progress towards a larger goal.
-7-
Teachers become masters at error analysis, tracking down and addressing the root of a problem.
In technology, at least as much time is spent identifying and fixing problems as is spent on building new systems.
Scanning through lines of code looking for the bug is very similar to reading through lines of a student’s work looking for their error. And in both cases, identifying the error is only the first step. The more important part is understanding why it occurred and how to remediate the problem.
-8-
Teachers have to become comfortable and adept at improvising when things don’t go as planned.
In technology, it is critical to be able to figure out a new path when an obstacle arises.
Whether it’s an unplanned fire drill that cuts class time down to 10 minutes or the internet going down at the beginning of a technology-focused lesson, teachers have to be good at thinking on the fly. The tech world may have fewer unplanned fire drills, but the forced deviations from a plan are just as numerous. It’s helpful to have people around that can navigate those without frustration or overwhelm.
-9-
Teachers have tremendous experience in working with diverse groups of people that often have different perspectives and experiences.
Technology brings together people from all backgrounds and the best results come from teams that can effectively work together.
Teachers know how to collaborate, working together to achieve a goal and utilizing the talents that each person brings to the table. They are comfortable in diverse groups and skilled at guiding conversations that contain many different views and ideas.
-10-
Teachers are experts at both asking and using questions.
Technology is a tool that is at its best when it arises from great questions and never refrains from questioning its conclusions.
Contrary to how many people view teachers, they actually spend more time asking rather than telling: How do you know that? Why did that happen? What would happen if…? Questions like that are critical in tech, where it is all-too-easy to adopt a narrow focus that fails to challenge itself. Questioners improve both process and product.
-11-
Teachers are used to working with constant – and rigid – deadlines.
In tech, deadlines are critical as projects move through the pipeline.
When the bell rings, the teacher HAS to be ready. As a result, teachers are used to deadlines and don’t have a problem with having deliverables ready on time.
-12-
Teachers know how to inspire and motivate a group.
Every team can benefit from a voice that helps each individual become their best.
In a well-run classroom, every student is celebrated for their strengths and encouraged to build upon them to become better. Defeat is viewed as a temporary condition and those struggles are used to build strength. “I can’t” is replaced with “I can’t yet, but I’m getting there.” Who wouldn’t want that same energy in their team?
Teachers can teach.
And they can also do so much more.
Lesson of the Day
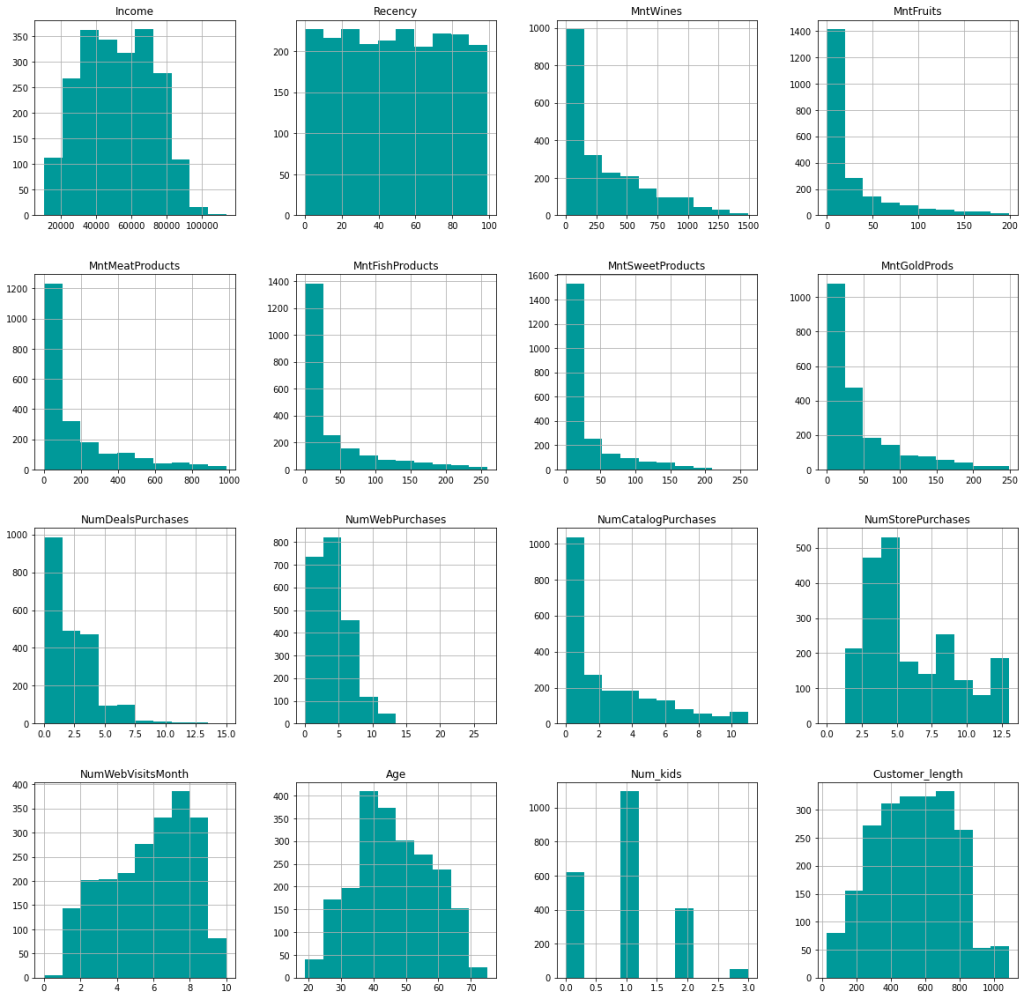
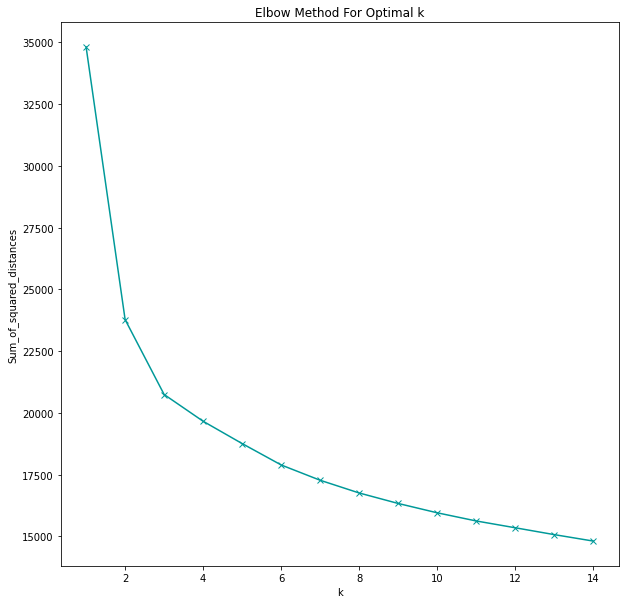
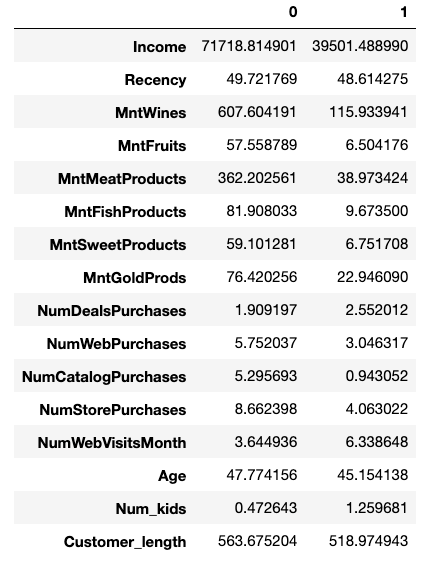
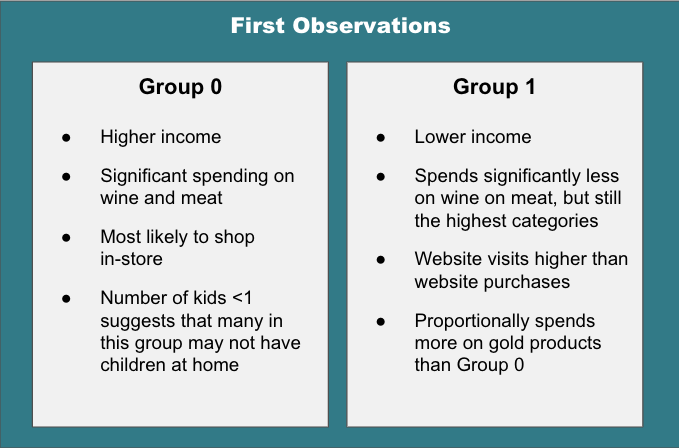
Other than guided exercises, I have not yet used map in Python (a combination of loving comprehensions and not taking the time to understand map). After reading through a brief tutorial on how map works, I’m now actively looking for opportunities to practice it.

Frustration of the Day
This is actually more of a sad than a frustration. A few conversations this week really ignited my teacher guilt about leaving. I just keep telling myself that they will be okay.

Win of the Day
I just received the pre-work material for my bootcamp program with the caveat that it may be difficult. I looked through it and nothing was unfamiliar. That would NOT have been the case a year ago!

Current Standing on the Imposter Syndrome Scale
3/5